Why Your Intuition is Holding AI Back: The Bitter Lesson of Compute
A study companion to Phase 1, Week 3 — built around Rich Sutton's 2019 essay The Bitter Lesson: seventy years of AI research repeatedly showing that general methods which leverage computation beat human-knowledge approaches, and by a large margin. Listen to the audio overview, study the infographic, and read the synthesis below.
♪ Audio overview
◷ Infographic
✎ Written synthesis
Introduction: The Human Ego vs. The Machine
There is a seductive vanity in the way we approach artificial intelligence. We instinctively want to play the role of the wise mentor, molding silicon in our own image by gifting it the "wisdom" we have spent a lifetime acquiring. We try to hand-code the rules of logic, the nuances of language, and the structures of visual perception, convinced that the path to true intelligence must mirror our own internal experience.
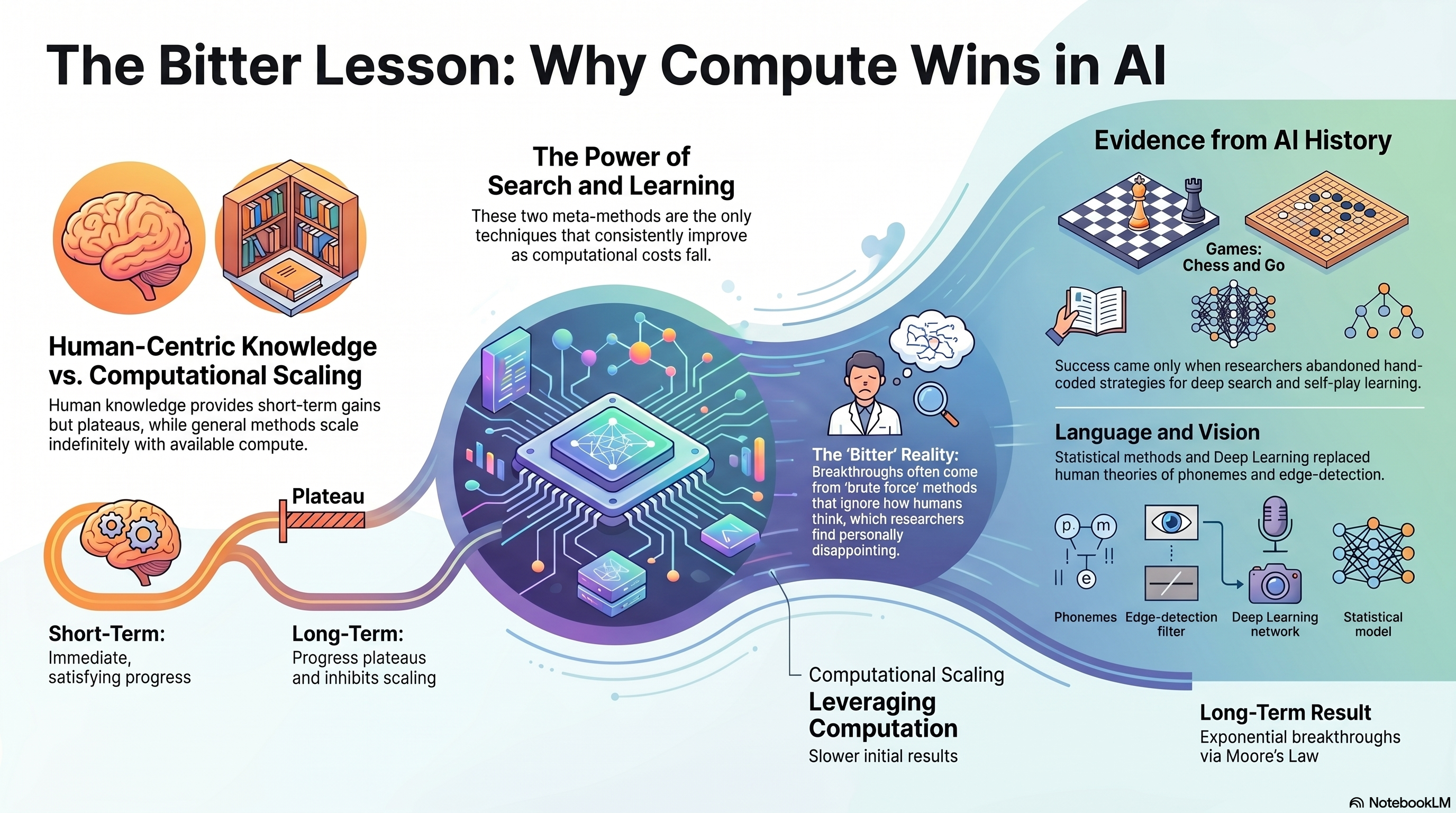
But the history of AI suggests that this desire to "teach" the machine is actually a form of intellectual vanity that holds the field back. In his seminal essay, "The Bitter Lesson," Rich Sutton outlines a recurring, humbling realization: human-centric methods—those built on our own intuition and expertise—consistently fail when pitted against general-purpose methods that simply leverage computation. This is a journey through seventy years of research that repeatedly proves that our "wisdom" is often the very thing standing in the way of progress.
The "Bitter" Truth: Why Human Knowledge is a Short-Term Fix
Leveraging human knowledge is a "psychological commitment" that offers an immediate, satisfying hit of progress. When a researcher builds their personal understanding of a domain into a system, they often see a quick performance boost. However, this is a strategic trap.
The trade-off is zero-sum: every hour spent hand-coding human-centric rules is an hour not spent developing general methods that can utilize the exponential growth of computing power. Sutton's "bitter" reality is that these human-knowledge approaches eventually plateau and become a bottleneck, preventing systems from taking advantage of more compute. Our expertise doesn't just fail to scale; it actively complicates the system in ways that make it less suited for the massive computation inevitably provided by Moore's Law.
"The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin."
Takeaway 1: The Chess and Go Delusion
The history of computer games serves as a masterclass in the failure of human-centric design. For years, researchers resisted "brute force" search, preferring methods that leveraged the "special structure" of chess as understood by masters. When Deep Blue defeated Garry Kasparov in 1997, it did so by utilizing special hardware and software to perform massive, deep search.
The research community did not celebrate this as a triumph of general strategy; instead, they were "not good losers," feeling a sense of dismay because the victory didn't come from human-like intuition. They dismissed search as a "not general strategy," even as it proved vastly more effective than their favored methods.
A similar, more modern delusion occurred with Go. Researchers spent decades trying to avoid search by incorporating human knowledge of the game's features. These efforts were eventually proven to be "irrelevant, or worse," once researchers embraced search and learning at scale—specifically through self-play. This success remains "tinged with bitterness" because it confirms a painful truth: the human-centric approaches researchers favored were not only unnecessary but were actually a distraction from the methods that ultimately achieved mastery.
Takeaway 2: Moore's Law is the Ultimate Arbiter
The reason these lessons are so bitter is Moore's Law. While researchers often conduct their work as if computation is a constant, the falling cost of compute is the only real constant in the long run. Human-engineered rules provide a fixed advantage that quickly shrinks toward zero as available hardware improves.
The scalability of general methods. Search and learning are not just useful tools; they are the only two classes of techniques that seem to scale "arbitrarily" or "indefinitely." Because these general methods are designed to soak up as much computation as possible, they are the only strategies that thrive over decades. Methods that rely on human-designed content effectively "cap" a system's potential, ensuring that as more compute becomes available, the system is unable to put it to good use.
Takeaway 3: The Shift from Content to Meta-Methods
Sutton's core philosophical argument is that we must stop trying to build in what we think we know. Things like space, objects, and phonemes are not simple truths; they are part of the "arbitrary, intrinsically-complex" outside world. Trying to model them is a fool's errand because their complexity is endless.
The strategic shift must be toward "meta-methods." Instead of building in our discoveries, we should build in the methods of discovery. We must accept that the search for good approximations of the world's complexity should be performed "by our methods, not by us."
"We want AI agents that can discover like we can, not which contain what we have discovered."
By attempting to build in our own discoveries, we make it harder for the AI to develop its own discovering process, essentially blinding the machine with our own limited perspectives.
Takeaway 4: The Failure of Hand-Engineered Vision and Speech
The evolution of speech recognition and computer vision represents a "colossal waste of researcher's time" spent trying to force machines to work the way we think our minds work. In the 1970s DARPA competition, human-centric models of the vocal tract and phonemes were soundly defeated by newer, more computational statistical methods based on Hidden Markov Models (HMMs). This pattern repeated in vision, where hand-engineered features were discarded once deep learning proved it could learn more effectively from data.
The evolution of methods:
- Discarded human-centric features: vocal tract models, hand-coded phonemes, SIFT features, "generalized cylinders," and edge detection.
- Winning computational methods: Hidden Markov Models (HMMs), statistical methods, deep learning (convolutions), and learning through self-play on massive datasets.
Conclusion: Embracing the Machine's Way
The field of AI is caught in a cycle of repeating its most expensive mistake: "building in" our own intuition. While it is personally satisfying to see a machine act on our instructions, that satisfaction comes at the cost of long-term progress. True breakthroughs only arrive when we abandon our human-centric pride and allow the machine to leverage computation to find its own way.
We are still making these mistakes today, continuing to try to find simple ways to model the "contents of minds." The question for the next generation of researchers is simple: are you willing to let go of the desire to be a teacher and instead become an architect of the discovery process itself? True AI progress requires us to stop modeling the world for the machine and start building the meta-methods that allow the machine to discover the world for itself.